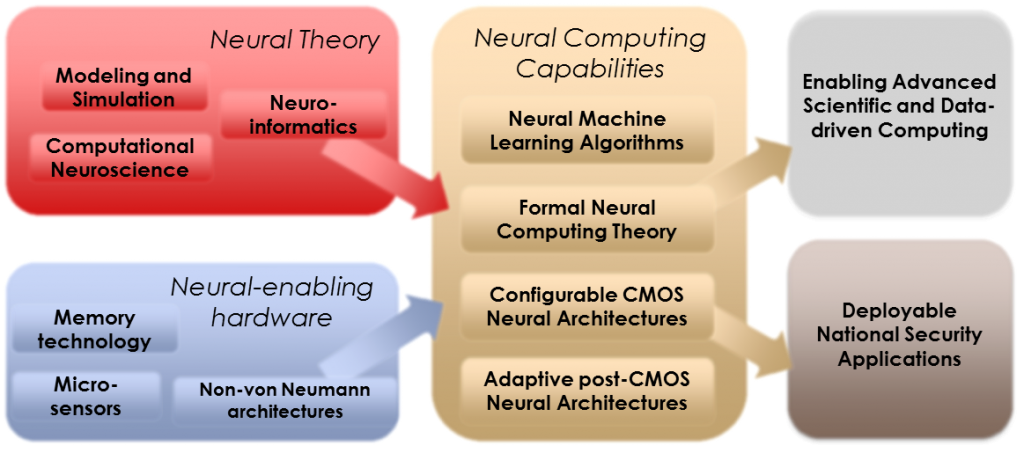
Neural computing research at Sandia covers the full spectrum from theoretical neuroscience to neural algorithm development to neuromorphic architectures and hardware. The neural computing effort is directed at impacting a number of real-world applications relevant to national security. These applications include improved cyber security and cyber defenses, embedded pattern recognition and data analytics systems, and neural-inspired approaches to improving scientific computing and high performance computing.
Neural Machine Learning
Neural-inspired machine learning algorithms such as deep neural networks and sparse coding systems have greatly impacted a number of data analytics domains. Our focus is on identifying paths to better leverage neuroscience knowledge in the development of novel and extension of existing neural machine learning techniques. Areas of research include:
- Enabling continuous learning in deep learning algorithms by incorporating neural processes such as adult neurogenesis (see Draelos et al., International Conference of Learning Representations).
- Developing models of content-addressible memory based on the hippocampus circuit architecture.
Formal Neural Computing Theory
While neural computing has often been identified as a post-von Neumann architecture option as computing moves into a post-Moore’s Law era, the precise computational benefits offered by neural approaches have been challenging to pin down. Sandia is developing formal theoretical computing approaches to identify the aspects of neural computation that will yield the highest application benefit. These approaches have focused on three domains: the use of spike-based representations, the ability to colocalize processing and memory, and the incorporation of continuous learning and adaptivity in a comptuing system.
Neural Computing Architectures
The development of effective neural computing architectures requires not only the design of physical systems capable of simultaneously processing thousands or millions of neurons and synapses, but also the development of software interfaces and APIs to allow algorithm development and systematic validation and verificatino techniques to ensure the noise-tolerance and real-world validiy of these systems. Through the HAANA Grand Challenge, Sandia is vertically developing two different neuromorphic computing architectures.
- The spike-timing processing unit (STPU) is an event driven architecture leveraging existing CMOS technologies to rapidly process streaming data in the spiking domain.
- The resistive memory crossbar (ReRAM) is a crossbar based architecture leveraging novel resistive memory devices (e.g., memristors) to process synaptic operations in the analog domain. See sidebar.
See the NERL Lab page for more information about our testing of different neuromorphic platforms.
Neuromorphic Devices
The large scale of biological neural systems is already challenging the upper limits of CMOS electronics technologies, and thus the development of novel devices which can acheive the high densities and lower power operation will be critical for scaling neuromorphic systems to biologically-relevant scales. Resistive memory technology is uniquely suited for neural applications, as not only do they enable high density synaptic connectivty but also provide a mechanism for synaptic-like learning without substantial external control circuitry.
Featured Project
The STPU Architecture
A challenge for neuromorphic computing is to develop architectures that enable complex connectivity between neurons, and specifically wtih the ability to incorporate spike timing into the architecture. The Sandia Spiking Temporal Processing Unit, or STPU, is designed to directly implement temporal neural processing in hardware. This use of timing has the potential to enable dramatically lower energy consumption during implementation of neural machine learning algorithms for pattern recognition and more directly enable the development of novel neural algorithms that operate in the time domain.
For more information, see Hill et al., ICRC 2017
Selected References
Cardwell S, Vineyard CM, Severa W, Chance F, Rothganger F, Wang F, Musuvathy S, Teeter CM, and Aimone JB – “Truly heterogeneous HPC: co-design to achieve what science needs from HPC” 2020 Smokey Mountains Computational Sciences and Engineering Conference (SMC2020)
Smith JD, Severa W, Hill AJ, Reeder L, Franke B, Lehoucq RB, Parekh O, and Aimone JB – “Solving a steady-state PDE using spiking networks and neuromorphic hardware” 2020 International Conference on Neuromorphic Systems, July 2020Aimone JB, Ho Y, Parekh O, Phillips CA, Pinar A, Severa W, Wang Y [alphabetical] – “Brief Announcement: Provable Neuromorphic Advantages for Computing Shortest Paths” 2020 Symposium on Parallelism in Algorithms and Architectures (SPAA), July 2020
Aimone JB, Severa W, and Vineyard CM – “Composing Neural Algorithms with Fugu” 2019 International Conference on Neuromorphic Systems, July 2019
Aimone JB, Parekh O, Phillips C, Pinar A, Severa W, and Xu H [alphabetical]– “Dynamic Programming with Spiking Neural Computing” 2019 International Conference on Neuromorphic Systems, July 2019
Vineyard CM, Dellana R, Aimone JB, Rothganger F, Severa WM – “Low-Power Deep Learning Inference using the SpiNNaker Neuromorphic Platform” 2019 Neuro-Inspired Computational Elements, March 2019
Severa W, Vineyard CM, Dellana R, Verzi SJ, and Aimone JB – “Training Deep Neural Networks for Binary Communication with the Whetstone Method” Nature Machine Intelligence. February 2019
Quach TT, Agarwal SA, James CD, Marinella M, and Aimone JB – “Fast Data Acquisition for Volatile Memory Forensics on Emerging Memory Architectures” – IEEE Access. December 2018
Aimone JB, Hamilton KE, Mniszewski S, Reeder L, Schuman CD, and Severa WM [alphabetical]– “Non-neural network applications for spiking neuromorphic hardware” – Proceedings of Third International Workshop on Post-Moore’s Era Supercomputing 2018
Verzi SJ, Rothganger F, Parekh OD, Quach T, Miner NE, Vineyard CM, James CD, and Aimone JB – “Computing with Spikes: The advantage of fine-grained timing” Neural Computation. 30(10) October 2018
Severa W, Lehoucq R, Parekh O, and Aimone JB – “Spiking Neural Algorithms for Markov Process Random Walk”– 2018 International Joint Conference on Neural Networks (IJCNN)
Parekh O, Phillips C, James CD, and Aimone JB – “Constant depth and sub-cubic size threshold circuits for matrix multiplication” – 2018 Symposium on Parallel Architectures and Applications (SPAA) Wang F, Quach TT, Wheeler J, Aimone JB, and James CD – “Sparse Coding for N-Gram Feature Extraction and Training for File Fragment Classification” – IEEE Transactions on Information Forensics and Security.
Hill AJ, Donaldson JW, Rothganger FH, Vineyard CM, Follett DR, Follett PL, Smith MR, Verzi SJ, Severa W, Wang F, Aimone JB, Naegle JH, and James CD – “A Spike-Timing Neuromorphic Architecture” Proceedings of the IEEE International Conference on Rebooting Computing October 2017
Severa W, Parekh O, Carlson KD, James CD, and Aimone JB – “Spiking Network Algorithms for Scientific Computing” – Proceedings of the IEEE International Conference on Rebooting Computing October 2016
Rothganger F – “Computing with dynamical systems” – Proceedings of the IEEE International Conference on Rebooting Computing October 2016
Vineyard CM and Verzi SJ – “Overcoming the Static Learning Bottleneck – the Need for Adaptive Neural Learning” – Proceedings of the IEEE International Conference on Rebooting Computing October 2016
Agarwal S, Plimpton SJ, Hughart DR, Hsia AH, Richter I, Cox JA, James CD, and Marinella MJ – “Resistive Memory Device Requirements for a Neural Algorithm Accelerator” Proceedings of the International Joint Conference on Neural Networks 2016
Draelos TJ, Miner NE, Cox JA, Lamb CC, James CD, and Aimone JB – “Neurogenic Deep Learning” Proceedings of the International Conference on Learning Representations 2016
Agarwal S, Quach T, Parekh OD, Hsia AH, Debenedictis EP, James CD, Marinella M, and Aimone JB – “Energy Scaling Advantages of Resistive Memory Crossbar Based Computation and its Application to Sparse Coding” Frontiers in Neuromorphic Engineering. January 2016
Cox JA, James CD, and Aimone JB – “A Signal Processing Approach for Cyber Data Classification with Deep Neural Networks” Complex Adaptive Systems – Procedia Computer Science. 61, November 2015
Vineyard CM, Verzi SJ, James CD, Aimone JB, and Heileman GL – “MapReduce SVM Game” INNS Conference on Big Data – Procedia Computer Science. 53, August 2015
Vineyard CM, Verzi SJ, James CD, Aimone JB, and Heileman GL – “Repeated Play of the SVM Game as a Means of Adaptive Classification” Proceedings of International Joint Conference on Neural Networks July2015
Rothganger F, Evans BR, Aimone JB, and DeBenedictis EP – “Training neural hardware with noisy components” Proceedings of International Joint Conference on Neural Networks July 2015
Marinella MJ, Mickel PR, Lohn AJ, Hughart DR, Bondi R, Mamaluy D, Mjalmarson H, Stevens JE, Decker S, Apodaca R, Evans B, Aimone JB, Rothganger F, James CD, and Debendictis EP – “Development, Characterization, and Modeling of a TaOx ReRAM for a Neuromorphic Accelerator”, ESC Transactions, 64 (14) 2014
Lohn AJ, Mickel PR, Aimone JB, Debenedictis EP, and Marinella MJ – “Memristors as synapses in artificial neural networks: Biomimicry beyond weight change” In Cybersecurity Systems for Human Cognition Augmentation. 2014